

 Open Library
Open Library








Frequently Asked Questions
[ The Internet Archive | Search Tips | Prelinger Movies | The Wayback Machine | Audio | MS-DOS Emulation | Archive BitTorrents | Accounts Information | Navigation | Live Music Archive | Movies | Collections | Law Enforcement Requests | The Internet Arcade | Uploading Content | Books and Texts | Rights | Downloading Content | Item page management | Borrow from Lending Library | The Grateful Dead Collection | Report Item | Forums | SFLan | Archive-It | Equipment | Errors ]
The Internet ArchiveDoes the Archive issue grants? No; although we promote the development of other Internet libraries through online discussion, colloquia, and other means, the Archive is not a grant-making organization. Yes, please do. Our BitCoin address is: 1Archive1n2C579dMsAu3iC6tWzuQJz8dN . Every bit helps. What is the nonprofit status of the Internet Archive? From where does its funding come? The Internet Archive is a 501(c)(3) nonprofit organization. It receives in-kind and financial donations from a variety of sources as well as you. How do I get assistance with research? How about research about a particular book? The Internet Archive focuses on preservation and providing access to digital cultural artifacts. For assistance with research or appraisal, you are bound to find the information you seek elsewhere on the internet. You may wish to inquire about reference services provided by your local public library. Your area's college library may also support specialized reference librarian services. We encourage your support of your local library, and the essential services your library's professional staff can provide in person. Local libraries are still an irreplaceable resource! What statistics are available about use of Archive.org?
What user stats do you keep and share? Where are they? What is a "view"? How often are they counted? Other Internet Archive stats links What's the significance of the Archive's collections?
Societies have always placed importance on preserving their culture and heritage. But much early 20th-century media -- television and radio, for example -- was not saved. The Library of Alexandria -- an ancient center of learning containing a copy of every book in the world -- disappeared when it was burned to the ground. |
Search TipsOn archive.org there is an "Advanced Search" link just below the search input field. For searches done in the search field in the top black nav bar the "Advanced Search" link will be present on the search results page just below the search input field. What search APIs are available Information about how to use the various search APIs can be found at https://archive.org/help/aboutsearch.htm
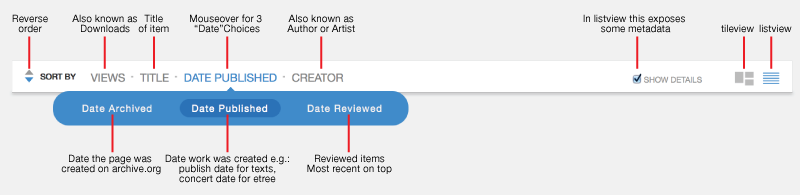
The "SORT BY" bar has options to allow you to control which results are displayed, in what order and what "view": How do I search just within a collection?
On a collection page there will be a "Search this Collection" input field on the right side of the page. Enter a term there and hit your return/enter key. The results will be of items in that collection. For advanced boolean search you can use "AND collection:[IDENTIFIER]" in your query. How can I use list view instead of tile view? For most search results pages you can choose the view in the "Sort by" bar; Tile view (the icon with three rectangles) or List view (the icon with multiple lines.) Tile view is the default view. What is indexed in the search engine? Only the metadata in an item page is indexed. So the search engine does not have the text of books, individual file metadata or embedded metadata. Can I search by Creative Commons license?
Yes, you can. But it's a little complicated. Here's how to break it down. See the license types at creative commons. When you want to find all of the items assigned a certain license by an uploading party, you'll plug their abbreviation for it into this search query: /metadata/licenseurl:http*abbreviation/* So if you're looking for Attribution Non-commercial No Derivatives (by-nc-nd), you'd put this in the search box: /metadata/licenseurl:http*by-nc-nd/*. If you want to use this in combination with other queries, like "I want by-nc-nd items about dogs" you'd do this: /metadata/licenseurl:http*by-nc-nd/* AND dog. The AND tells the search engine all the items returned should have that license AND they should contain the word dog. AND has to be in all caps. Just to make it easier, here are the basic searches: |
QuestionsHow did you digitize the films? Do I need to inform the Internet Archive and/or Prelinger Archives when I reuse these movies? How can I get access to stock footage from these films? An article on re-coding Prelinger Archive films to SVCD so you can watch them on your DVD player. Do I need to credit the Internet Archive and Prelinger Archives when I reuse these movies? What parameters were used when making the Real Media files on the website? Are there restrictions on the use of the Prelinger Films? Can you point me to resources on the history of ephemeral films? Why are there very few post-1964 movies in the Prelinger collection? |
Prelinger MoviesHow did you digitize the films? The Prelinger Archives films are held in original film form (35mm, 16mm, 8mm, Super 8mm, and various obsolete formats like 28mm and 9.5mm). Films were first transferred to Betacam SP videotape, a widely used analog broadcast video standard, on telecine machines manufactured by Rank Cintel or Bosch. The film-to-tape transfer process is not a real-time process: It requires inspection of the film, repair of any physical damage, and supervision by a skilled operator who manipulates color, contrast, speed, and video controls. The videotape masters created in the film-to-tape transfer suite were digitized in 2001-2003 at Prelinger Archives in New York City using an encoding workstation built by Rod Hewitt. The workstation is a 550 MHz PC with a FutureTel NS320 MPEG encoder card. Custom software, also written by Rod Hewitt, drove the Betacam SP playback deck and managed the encoding process. The files were uploaded to hard disk through the courtesy of Flycode, Inc. More recently, Prelinger films have been digitized and uploaded by Skip Elsheimer at AV Geeks. We are also digitizing home movies and other materials on Internet Archive's ScanStation scanner. The files were encoded at constant bitrates ranging from 2.75 Mbps to 3.5 Mbps. Most were encoded at 480 x 480 pixels (2/3 D1) or 368 x 480 (roughly 1/2 D1). The encoder drops horizontal pixels during the digitizing process, which during decoding are interpolated by the decoder to produce a 720 x 480 picture. (Rod Hewitt's site Coolstf shows examples of an image before and after this process.) Picture quality is equal to or better than most direct broadcast satellite television. Audio was encoded at MPEG-1 Level 2, generally at 112 kbps. Both the MPEG-2 and MPEG-4 movies have mono audio tracks. To convert the MPEG-2 video to MPEG-4, we used a program called FlasK MPEG. This is an MPEG-1/2 to AVI conversion tool that reads the source MPEG-2 and outputs an AVI file containing the video in MPEG-4 format and audio in uncompressed PCM format. We then use a program called Virtual Dub that recompresses the audio using the MPEG-1 Level 3 (MP3) format. This process is automated by the software that runs the system. Do I need to inform the Internet Archive and/or Prelinger Archives when I reuse these movies? No. However, we would very much like to know how you have used this material, and we'd be thrilled to see what you've made with it. This may well help us improve this site. Please consider sending us a copy of your production (postal mail only), and let us know whether we can call attention to it on the site. Our address is: Rick Prelinger How can I get access to stock footage from these films? Access to the movies stored on this site in videotape or film form is available to commercial users through Getty Images, representing Prelinger Archives for stock footage sales. Please contact Getty Images directly: Please visit us at www.prelinger.com/prelarch.html for more information on access to these and similar films. Prelinger Archives regrets that it cannot generally provide access to movies stored on this Web site in other ways than through the site itself. We recognize that circumstances may arise when such access should be granted, and we welcome email requests. Please address them to Rick Prelinger. The Internet Archive does not provide access to these films other than through this site. An article on re-coding Prelinger Archive films to SVCD so you can watch them on your DVD player. See archived version of www.moviebone.com/ Do I need to credit the Internet Archive and Prelinger Archives when I reuse these movies? We ask that you credit us as a source of archival material, in order to help make others aware of this site. We suggest the following forms of credit: Archival footage supplied by Internet Archive (at archive.org) in association with Prelinger Archives or Archival footage supplied by Internet Archive (at archive.org) or "Archival footage supplied by archive.org" What parameters were used when making the Real Media files on the website? Rod Hewitt posted some very useful information here Are there restrictions on the use of the Prelinger Films? The films are available for reuse according to the Creative Commons licenses, if any, that appear with on each film's detail page. Pursuant to the Creative Commons license, you are warmly encouraged to download, use and reproduce these films in whole or in part, in any medium or market throughout the world. You are also warmly encouraged to share, exchange, redistribute, transfer and copy these films, and especially encouraged to do so for free. Any derivative works that you produce using these films are yours to perform, publish, reproduce, sell, or distribute in any way you wish without any limitations. Descriptions, synopses, shotlists and other metadata provided by Prelinger Archives to this site are copyrighted jointly by Prelinger Archives and Getty Images. They may be quoted, excerpted or reproduced for educational, scholarly, nonprofit or archival purposes, but may not be reproduced for commercial purposes of any kind without permission. If you require a written license agreement or need access to stock footage in a physical format (such as videotape or a higher-quality digital file), please contact Getty Images. The Internet Archive does not furnish written license agreements, nor does it comment on the rights status of a given film above and beyond the Creative Commons license. We would appreciate attribution or credit whenever possible, but do not require it.
Can you point me to resources on the history of ephemeral films? See the bibliography and links to other resources at www.prelinger.com/ephemeral.html. Why are there very few post-1964 movies in the Prelinger collection? Largely because of copyright law. While a high percentage of ephemeral films were never originally copyrighted or (if initially copyrighted) never had their copyrights properly renewed, copyright laws still protect most moving image works produced in the United States from 1964 to the present. Since the Prelinger collection on this site exists to supply material to users without most rights restrictions, every title has been checked for copyright status. Those titles that either are copyrighted or whose status is in question have not been made available. For information on recent changes in copyright law, see the circular Duration of Copyright (in PDF format) published by the Library of Congress Check out our Prelinger Archives Forum |
QuestionsCan I link to old pages on the Wayback Machine? Who was involved in the creation of the Internet Archive Wayback Machine? How was the Wayback Machine made? How do you archive dynamic pages? How can I have my site's pages excluded from the Wayback Machine? Do you collect all the sites on the Web? Why isn't the site I'm looking for in the archive? Why is the Internet Archive collecting sites from the Internet? What makes the information useful? Is there any personal information in these collections? Can I add pages to the Wayback Machine? How do I contact the Internet Archive? Where is the rest of the archived site? Why am I getting broken or gray images on a site? Why are some sites harder to archive than others? How do you protect my privacy if you archive my site? What is the Wayback Machine? How can I get my site included in the Wayback Machine? How does the Wayback Machine behave with Javascript turned off? Where does the name come from? How do I cite Wayback Machine urls in MLA format? What is the Archive-It service of the Internet Archive Wayback Machine? How can I help the Internet Archive and the Wayback Machine? Who has access to the collections? What about the public? How can I get pages authenticated from the Wayback Machine? How can use the pages in court? Some sites are not available because of robots.txt or other exclusions. What does that mean? |
The Wayback MachineCan I link to old pages on the Wayback Machine? Yes! The Wayback Machine is built so that it can be used and referenced. If you find an archived page that you would like to reference on your Web page or in an article, you can copy the URL. You can even use fuzzy URL matching and date specification... but that's a bit more advanced. Who was involved in the creation of the Internet Archive Wayback Machine? "The original idea for the Internet Archive Wayback Machine began in 1996, when the Internet Archive first began archiving the web. Now, five years later, with over 100 terabytes and a dozen web crawls completed, the Internet Archive has made the Internet Archive Wayback Machine available to the public. The Internet Archive has relied on donations of web crawls, technology, and expertise from Alexa Internet and others. The Internet Archive Wayback Machine is owned and operated by the Internet Archive." How was the Wayback Machine made? Alexa Internet, in cooperation with the Internet Archive, has designed a three dimensional index that allows browsing of web documents over multiple time periods, and turned this unique feature into the Wayback Machine. How do you archive dynamic pages? There are many different kinds of dynamic pages, some of which are easily stored in an archive and some of which fall apart completely. When a dynamic page renders standard html, the archive works beautifully. When a dynamic page contains forms, JavaScript, or other elements that require interaction with the originating host, the archive will not contain the original site's functionality. Using the Internet Archive Wayback Machine, it is possible to search for the names of sites contained in the Archive (URLs) and to specify date ranges for your search. We hope to implement a full text search engine at some point in the future. How can I have my site's pages excluded from the Wayback Machine? You can exclude your site from display in the Wayback Machine by placing a robots.txt file on your web server that is set to disallow User-Agent: ia_archiver. You can also send an email request for us to review to info@archive.org with the URL (web address) in the text of your message. Do you collect all the sites on the Web? No, the Archive collects web pages that are publicly available. We do not archive pages that require a password to access, pages that are only accessible when a person types into and sends a form, or pages on secure servers. Pages may not be archived due to robots exclusions and some sites are excluded by direct site owner request. Why isn't the site I'm looking for in the archive? Some sites may not be included because the automated crawlers were unaware of their existence at the time of the crawl. It's also possible that some sites were not archived because they were password protected, blocked by robots.txt, or otherwise inaccessible to our automated systems. Site owners might have also requested that their sites be excluded from the Wayback Machine. Why is the Internet Archive collecting sites from the Internet? What makes the information useful? Most societies place importance on preserving artifacts of their culture and heritage. Without such artifacts, civilization has no memory and no mechanism to learn from its successes and failures. Our culture now produces more and more artifacts in digital form. The Archive's mission is to help preserve those artifacts and create an Internet library for researchers, historians, and scholars. The Archive collaborates with institutions including the Library of Congress and the Smithsonian. No, we do not collect or archive chat systems or personal email messages that have not been posted to Usenet bulletin boards or publicly accessible online message boards. How can I get a copy of the pages on my Web site? If my site got hacked or damaged, could I get a backup from the Archive?' Our terms of use do not cover backups for the general public. However, you may use the Internet Archive Wayback Machine to locate and access archived versions of a site to which you own the rights. We can't guarantee that your site has been or will be archived. We can no longer offer the service to pack up sites that have been lost. Is there any personal information in these collections? We collect Web pages that are publicly accessible. These may include pages with personal information. Can I add pages to the Wayback Machine? On https://archive.org/web you can use the "Save Page Now" feature to save a specific page one time. This does not currently add the URL to any future crawls nor does it save more than that one page. It does not save multiple pages, directories or entire sites. How do I contact the Internet Archive? All questions about the Wayback Machine, or other Internet Archive projects, should be addressed to info@archive.org. Where is the rest of the archived site? Why am I getting broken or gray images on a site? Broken images occur when the images are not available on our servers. Usually this means that we did not archive them. You can tell if the image or link you are looking for is in the Wayback Machine by entering the image or link’s URL into the Wayback Machine search box. Whatever archives we have are viewable in the Wayback Machine. The best way to see all the files we have archived of the site is: http://web.archive.org/*/www.yoursite.com/* There is a 3-10 hour lag time between the time a site is crawled and when it appears in the Wayback Machine.
Why are some sites harder to archive than others? If you look at our collection of archived sites, you will find some broken pages, missing graphics, and some sites that aren't archived at all. Some of the things that may cause this are:
How do you protect my privacy if you archive my site?
The Archive collects Web pages that are publicly available, the same ones that you might find as you surfed around the Web. We do not archive pages that require a password to access, pages that are only accessible when a person types into and sends a form, or pages on secure servers. Pages tagged for robots.txt exclusion (for User-Agent: ia_archiver) by their owners are excluded from the Wayback Machine. We also provide information on removing a site from the collections. Those who use the collections must agree to certain terms of use. What is the Wayback Machine? How can I get my site included in the Wayback Machine?
The Internet Archive Wayback Machine is a service that allows people to visit archived versions of Web sites. Visitors to the Wayback Machine can type in a URL, select a date range, and then begin surfing on an archived version of the Web. Imagine surfing circa 1999 and looking at all the Y2K hype, or revisiting an older version of your favorite Web site. The Internet Archive Wayback Machine can make all of this possible. How can I get my site included in the Wayback Machine? Much of our archived web data comes from our own crawls or from Alexa Internet's crawls. Neither organization has a "crawl my site now!" submission process. Internet Archive's crawls tend to find sites that are well linked from other sites. The best way to ensure that we find your web site is to make sure it is included in online directories and that similar/related sites link to you. Alexa Internet uses its own methods to discover sites to crawl. It may be helpful to install the free Alexa toolbar and visit the site you want crawled to make sure they know about it. Regardless of who is crawling the site, you should ensure that your site's 'robots.txt' rules and in-page META robots directives do not tell crawlers to avoid your site. How does the Wayback Machine behave with Javascript turned off? If you have Javascript turned off, images and links will be from the live web, not from our archive of old Web files. How did I end up on the live version of a site? or I clicked on X date, but now I am on Y date, how is that possible? Not every date for every site archived is 100% complete. When you are surfing an incomplete archived site the Wayback Machine will grab the closest available date to the one you are in for the links that are missing. In the event that we do not have the link archived at all, the Wayback Machine will look for the link on the live web and grab it if available. Pay attention to the date code embedded in the archived url. This is the list of numbers in the middle; it translates as yyyymmddhhmmss. For example in this url http://web.archive.org/web/20000229123340/http://www.yahoo.com/ the date the site was crawled was Feb 29, 2000 at 12:33 and 40 seconds. You can see a listing of the dates of the specific URL by replacing the date code with an asterisk (*), ie: http://web.archive.org/*/www.yoursite.com Where does the name come from? The Wayback Machine is named in reference to the famous Mr. Peabody's WABAC (pronounced way-back) machine from the Rocky and Bullwinkle cartoon show. How do I cite Wayback Machine urls in MLA format? This question is a newer one. We asked MLA to help us with how to cite an archived URL in correct format. They did say that there is no established format for resources like the Wayback Machine, but it's best to err on the side of more information. You should cite the webpage as you would normally, and then give the Wayback Machine information. They provided the following example: McDonald, R. C. "Basic Canary Care." _Robirda Online_. 12 Sept. 2004. 18 Dec. 2006 [http://www.robirda.com/cancare.html]. _Internet Archive_. [ http://web.archive.org/web/20041009202820/http://www.robirda.com/cancare.html]. They added that if the date that the information was updated is missing, one can use the closest date in the Wayback Machine. Then comes the date when the page is retrieved and the original URL. Neither URL should be underlined in the bibliography itself. Thanks MLA! What is the Archive-It service of the Internet Archive Wayback Machine?
For information on the Archive-It subscription service that allows institutions to build and preserve collections of born digital content, see https://www.archive.org/about/faqs.php#Archive-It How can I help the Internet Archive and the Wayback Machine? The Internet Archive actively seeks donations of digital materials for preservation. If you have digital materials that may be of interest to future generations, please let us know by sending an email to info at archive dot org. The Internet Archive is also seeking additional funding to continue this important mission. You can click the donate tab above or click here. Thank you for considering us in your charitable giving. Who has access to the collections? What about the public? Anyone can access our collections through our website archive.org. The web archive can be searched using the Wayback Machine. The Archive makes the collections available at no cost to researchers, historians, and scholars. At present, it takes someone with a certain level of technical knowledge to access collections in a way other than our website, but there is no requirement that a user be affiliated with any particular organization. How can I get pages authenticated from the Wayback Machine? How can use the pages in court? The Wayback Machine tool was not designed for legal use. We do have a legal request policy found at our legal page. Please read through the entire policy before contacting us with your questions. We do have a standard affidavit as well as a FAQ section for lawyers. We would prefer that before you contact us for such services, you see if the other side will stipulate instead. We do not have an in-house legal staff, so this service takes away from our normal duties. Once you have read through our policy, if you still have questions, please contact us for more information. Some sites are not available because of robots.txt or other exclusions. What does that mean? Such sites may have been excluded from the Wayback Machine due to a robots.txt file on the site or at a site owner’s direct request. The Internet Archive strives to follow the Oakland Archive Policy for Managing Removal Requests And Preserving Archival Integrity
What is the Wayback Machine's Copyright Policy? The Internet Archive respects the intellectual property rights and other proprietary rights of others. The Internet Archive may, in appropriate circumstances and at its discretion, remove certain content or disable access to content that appears to infringe the copyright or other intellectual property rights of others. If you believe that your copyright has been violated by material available through the Internet Archive, please provide the Internet Archive Copyright Agent with the following information:
The Internet Archive strives to follow the Oakland Archive Policy intended for use by both academic and non-academic digital repositories and archivists. The Internet Archive Copyright Agent can be reached as follows: Internet Archive Copyright Agent |
QuestionsHow do I specify an image for my page? How do I link to a specific audio track? What are the other non-audio format files that were derived? How do I control the order of tracks in the playlist? What is the squiggly line in the player? How can I adjust the volume in the player? How can I play ogg or lossless formats (flac, wav, aiff, shn) files? How do I change the titles in the track playlist? Can I upload a zip file of audio tracks and have them be playable? Should I use the html5 or Flash player? How can I play a downloaded audio track? |
AudioHow do I specify an image for my page? Once you've uploaded it to the item follow this clickpath: Edit > change the information > scroll down to Files, formats and derivations > in dropdown menu next to the image file choose "Item Image" > click the "Submit" button. How do I link to a specific audio track? You would need the URL of the file to link to it. To get that click "SHOW ALL" link in the DOWNLOAD OPTIONS section of an item's details page. There you can control/right-click on the link to the file and copy the URL. An uploaded image file will automatically be displayed to the left of the audio player. Ideally the image would be at minimum 750p wide. Images should be jpg, png or gif format. What are the other non-audio format files that were derived?
These files are important for the display/setup/research of items. How do I control the order of tracks in the playlist? The order of the playlist is determined by the alphanumeric order of the file names, not the titles. To force a desired order you can add number prefixes to the file names. Always use the same amount of digits for the prefix so if there are more than 10 start with 01, more than 100 start with 001. As an example: 01trackone.flac 02tracktwo.flac 03trackthree.flac etc. What is the squiggly line in the player? The is a spectrogram representation of the volume of the audio track. It can be helpful to spot silences between sound or particularly loud or quite sections. This can help you locate sections you might want to find without having to listen to the entire track. It is not scrubbable. Move the play bar to move to another section of the track How can I adjust the volume in the player? At this time the volume is an on/off toggle. To control the volume use the volume adjust on your computer or device. Click the "Share" icon near the player. A popup window will offer URLs for embedding. For more advance options click the "Advanced embedding details, examples, and help!" link at the bottom of the popup. How can I play ogg or lossless formats (flac, wav, aiff, shn) files? There are many players available for these formats. Some are free, some are devices. Search online for ogg player or flac player to get started. How do I change the titles in the track playlist?
Follow this clickpath: Can I upload a zip file of audio tracks and have them be playable? For audio item files in compressed formats (zip, tar, etc.) will neither be derive to other formats nor be used by the audio player. You should upload the files as separate files. Should I use the html5 or Flash player? The html5 audio player is the default player. Some browsers may prefer to use Flash. Clicking the "lightning bolt" icon on the right side of the player will with it to a Flash based player. How can I play a downloaded audio track? There are many players available. Many come standard on devices such as Quicktime (Mac) or Windows Media Player (PC). You can search for others online. VLC is a nice and flexible free player for audio and video. What is the bitrate of derived audio files? VBR MP3 and ogg files that are derived from other formats are typically in the 150-200mbps bitrate range. What kind of audio file should I submit? The archive is all about free access to information, so you should submit file formats that are easily downloadable and/or streamable for other site patrons. We prefer that you submit the highest quality file that you have available. We will attempt to create smaller file sizes and formats automatically with our deriver program. We recommend that you do not attempt to do any special encoding of your files - the more settings you mess around with, the less likely our deriver code will be able to process the file. If you are submitting a Live Music Archive item, please only submit lossless formats such as flac, wav, aiff or shn files. Even for non-LMA items, these are the best formats to use. Whatever format you choose, please upload each file to your item individually (you can submit multiple files per item), in a non-compressed format. Uploading content in a .zip or .rar file makes your item unstreamable and significantly less accessible to others. If you upload .zip, .rar, non-audio formats (like .exe), or password-protected files, they may be removed by our moderators. This page lists the file formats we will attempt to derive depending on what type of file you submit. |
MS-DOS EmulationThe Program is running WAY TOO FAST! Some of the programs running in EM-DOSBOX relied on timing loops and CPU types that the emulator is not showing. We're working on a solution where we can pre-repair the speed before running, but until then, there is a fix: While the program is running, press CTRL-F11 to slow the program down. Pressing CTRL-F11 repeatedly will slow it down further, until the speed is more reasonable. (Pressing CTRL-F12 repeatedly will attempt to speed things up.) I want to save my game! How do I do that? Currently, there is no way to save your game, although we are trying to work out if this is technologically possible. What is MS-DOS Emulation on the Internet Archive? The Internet Archive's software collections have a number of in-browser emulators to allow limited access to software, by making the software play within (most) browsers. The majority of this is done with the JSMESS (Javascript MESS) system, which is utilized in multiple collections, such as the Console Living Room or the Internet Arcade. For one collection, the MS-DOS Software Library, we have implemented the EM-DOSBOX emulator, which is based off of the DOSBOX project and which is designed specifically for DOS-compatible programs. I can see my mouse and the program's mouse. In the programs where a mouse cursor is provided, your mouse will generally work. However, to prevent both mouse cursors (the DOS cursor and your computer's cursor) from being on the screen at the same time, select the full screen option. I have questions or want to walk through a non-working program. The MS-DOS emulation is part of the Software Library of the Internet Archive, which is overseen by curator Jason Scott Please mail him at jscott@archive.org with any questions, suggestions or discussions. The EM-DOSBOX emulator is a javascript program running in a browser - it requires a lot of CPU to run, and definitely requires the most up-to-date browsers to take advantages of speed enhancements. We highly suggest you update to the latest Chrome or Firefox to ensure the program runs at top speed. The difference between versions even a few months or a year apart can be multiple times. In a few rare cases, the game or program being run does certain video or programming tricks that confuse the emulator, and the whole program runs notably slow, slower than even a taxed system should run. This is due to incompatibility with the emulator, and unfortunately will require the DOSBOX project to improve emulation going forward. It's not working for me. (Common Issues) As it is experimental and very new technology, there are a number of places that the MS-DOS Em-DOSBOX emulator can fail to work.
My Favorite Game isn't in there! What's wrong? There are multiple reasons the MS-DOS section might not have a game or application in its library. They include:
|
QuestionsHow do I edit metadata of my item? How do I find Torrents on the Archive? Can I download only part of an item using an Archive BitTorrent? My Torrent download never completes? My Torrent download never starts? How do I tell if a Torrent is being seeded? Does the Internet Archive run trackers? How do I use Torrents to upload to archive.org? How is the Internet Archive using BitTorrent? How to prevent an Archive Torrent from being made |
Archive BitTorrentsHow do I edit metadata of my item?
For existing items use this clickpath from the item's details page: You can only modify items that you created. How do I find Torrents on the Archive? You can search and browse all our Torrents on the Torrents collection homepage (or one of the media-specific subcollections). To narrow your own Search or Advanced Search query, add format:"Archive BitTorrent" to your search terms, e.g. https://archive.org/search.php?query='scifi AND mediatype:audio AND format:"Archive BitTorrent"'. The most popular and recent Torrents are available on each tracker's hotlists, e.g. bt1.archive.org Hot List. Can I download only part of an item using an Archive BitTorrent? Yes, almost all contemporary BitTorrent clients allow you to select which files included in the Torrent are downloaded. And even when you download only one or some files, you get the speed advantages of using the format. Many show a list of the files contained in the Torrent, and both folders and individual files can be selected or deselected both before, and during, download. It is recommend, in fact, that you deselect the top-level directory within the Torrent named ._____padding_file if there is one, as this contains unnecessary (empty) Internet Archive padding files. My Torrent download never completes? Most likely, you have an out-of-date Torrent for the Item you are trying to download. The first thing to try is re-downloading the Items' Torrent, and trying again. Torrents for Items on the Internet Archive can become obsolete when the Item the Torrent is for changes. In that case, some or (more rarely) all of the files within the Torrent will fail to download completely. This is because our Torrents rely heavily on webseeding (download directly from our servers, when no peers have the files you are seeking). When files on our servers have changed since the Torrent was made, they will not match expected 'piece hashes'; some BitTorrent clients (e.g. Transmission) will attempt to re-download file pieces from changed files over and over, forever, assuming there was an error in transmission, when in fact the file has changed. Torrents that never download at all most likely are the result of a different problem, lack of client support for Getright-style webseeding. My Torrent download never starts? It's worth mentioning that some BitTorrent clients take a very long time to begin downloading when relying on webseeding (a common requirement when using Archive BitTorrents). At times downloads can take upwards of several minutes to start. We're not sure exactly why; we suspect those clients exhaust all other options, such as DHT, before falling back on webseeds. (We have observed this behavior with Transmission.) If you download an up-to-date (current) Torrent from the Archive, and it loads into your BitTorrent client, but download never begins, the most likely cause is that you are using a BitTorrent client that does not support Getright-style webseeding. Our Torrents rely heavily on webseeding (download directly from our servers, when no peers have the files you are seeking). Some BitTorrent clients (e.g. rTorrent) do not support Getright-style webseeding, and will not be able to download un-seeded Internet Archive Torrents. At the moment, the only solution to this problem is to use a different client. Another possibility is that your Torrent file is out of date, because the Item has moved to a new server, and your client does not support redirection of our canonical webseeding URL (and no tracked or discoverable peers are seeding the Torrent). In this case, the problem can be solved by re-downloading the Torrent file. How do I tell if a Torrent is being seeded? Current seed and leech counts are displayed for each Archive Torrent on the relevant Item details pages, in parenthesis next to the Torrent link. These values are cached for five minutes or so, and because clients do not always update our trackers regularly, they may be somewhat out of date. The number of seeders is shown first, and the number of leechers (downloaders without the complete Torrent) second. The seeder number includes 'webseeds,' however, which are only usable by BitTorrent clients that support Getright-style webseeding. Does the Internet Archive run trackers? Yes, Internet Archive torrents are tracked by bt1.archive.org and bt2.archive.org. We are using opentracker, which has proven to be highly scalable. Our trackers are closed (they track our only own torrents). How do I use Torrents to upload to archive.org? Retrieval of Torrents is not the best solution for uploading unless you already have an existing mechanism for creating and seeding Torrents. This capability is not intended as an alternative to our uploader. It merely enables the Archive to capture material already being distributed via BitTorrent. Torrent retrieval by the Archive works like this: If a valid .torrent file is uploaded (e.g. through our Uploader) into an item, when that item is derived, we will instantiate a BitTorrent client (Transmission) and attempt to retrieve the Torrent. If the Torrent is successfully retrieved, its contents will be added to the item. 'Valid' in this case means, well-formed and seeded. Our client will attempt to scrape any listed trackers to find seeding peers, but will also attempt to find peers via DHT and can fall back on Getright-style webseeding when possible. The Torrent file itself is leeched only long enough to retrieve the file; we do not seed the Torrent after retrieval. However, all items contents, including those retrieved through this method, are made available via the item's own Archive Torrent. (Because it contains additional contents, this Archive Torrent will, alas, have a different infohash from the original Torrent. So uploading a Torrent to the Archive does not make us a seeder of it.) Bonus feature: if you have only a magnet link, and not a Torrent file, you can create a dummy .torrent file by pasting that magnet link into a text file and naming it foo.torrent. If you upload this dummy Torrent file, we'll detect that you gave us a magnet link and take care of the rest. How is the Internet Archive using BitTorrent? Downloading Internet Archive Content As of summer 2012, the Internet Archive is beta-testing the distribution of our public collections via the BitTorrent protocol (as a supplement to traditional HTTP download). Currently over 1.4 million Archive Items are available via the BitTorrent protocol, comprising almost a petabyte of public domain materials. As testing continues, more and more content will be made available through Torrents. For the details, see the related FAQ, Details of Archive-made Torrents. BitTorrent download requires an up-to-date BitTorrent client. For general information on the BitTorrent protocol, see Wikipedia or BitTorrent.com. Uploading BitTorrents to the Internet Archive Starting in 2011, the Internet Archive began automatically retrieving BitTorrent files uploaded into most Community collections. Uploading a Torrent provides a convenient way to upload many files or large contents, provided seeds (including webseeds) are available for the Torrent. How to prevent an Archive Torrent from being made Internet Archive BitTorrents are automatically made for community-contributed items in many collections, and automatically updated when item contents or metadata change. If you prefer that your item not have an Archive Torrent made for it; or that items within a collection you maintain do not, you can prevent Torrents from being made by including the following metadata tag in your item: noarchivetorrent=true Note: adding this tag does not remove existing Torrents, those must be removed using the Item Manager item file management tool. For instructions on how to edit an item or collection's metadata, see the FAQ Uploading Content.
Why is the Torrent link for an Item lined out (
While an Item is being updated, its Torrent link is temporarily disabled and shown as Changes to an item usually render any existing Archive BitTorrent for it obsolete. Attempts to download obsolete Archive Torrents will usually fail, as described here: My Torrent download never completes?. (Technically, the problem is that when files within an Item change, they can no longer download correctly via webseeding because the piece hashes for updated files change). The Torrent link will return to normal when the Item finishes updating and the torrent is updated. The Torrent link may be unavailable for a few minutes or a few hours depending on the size of the Item and how busy the Archive processing cluster is (in very rare cases, it might be disabled for a day or more). Note: obsolete torrents will continue to be tracked by Archive trackers for some time, but will only be retrievable when seeded by peers who have downloaded the referenced version of the item. What are peers, seeds, leechers, and snatches? BitTorrent is a peer-to-peer file-sharing protocol facilitated by centralized trackers. The Internet Archive runs several BitTorrent trackers to allow for peer discovery. Archive trackers track (but do not log or otherwise record) which peers have pieces of which Torrents; real-time statistics are summarized on tracker hotlists for each of our Trackers. Internet Archive tracker statistics of interest include:
Note: Internet Archive seeder and peer counts include webseeds; these seeds are available only when using clients that support Getright-style webseeding. |
QuestionsHow do I retrieve my password? Where is my account information? How can I change my account information? If I delete my account will all my uploads be deleted? I changed my email address and now I cannot access my items? How do I add an avatar image to my account page? How do I add an avatar image to my favorites page? I changed my user name but the identifier of my account page did not change? If I change my screen name will it change on my reviews and forums posts as well? |
Accounts InformationBookmarks are now referred to as "Favorites". To Favorite an item click the star icon that is in the top right area of an item details page to the right of the player. You can create a new account at the Create An Account page. Once you create an account you should receive a verification email (please check you spam/trash filed if you do not see it in your inbox). If responding to the verification email fails to activate your account please let us know by emailing to info@archive.org. How do I retrieve my password? On the login page you can click the "Forgot password?" link or go directly to Where is my account information?
Follow this clickpath: How can I change my account information?
Follow this clickpath:
Follow this clickpath: This cannot be reversed. Note: deleting your account will NOT remove any pages you created on the site. To do that you would need to send a request to info@archive.org. If I delete my account will all my uploads be deleted? No. Deleting your account will NOT remove any pages you created on the site. To do that you would need to send a request to info@archive.org. Please send it from the account email address if possible. Otherwise, please offer an explanation as to how we might verify that this is/was your account. I changed my email address and now I cannot access my items? To have existing items associated with a new account email address please email us at info@archive.org. Please include your previous email and the new email addresses. How do I add an avatar image to my account page? Simply drag an image over or mouseover the icon on your "My Library" page > click "Submit > wait for tasks to run and then refresh the page
Follow this clickpath: How do I add an avatar image to my favorites page? Simply drag an image over or mouseover the icon on your "My Favorites" page > click "Submit > wait for tasks to run and then refresh the page I changed my user name but the identifier of my account page did not change? The identifier of your account page is permanently established when you create your account. It will not change even if you change your screen name. If I change my screen name will it change on my reviews and forums posts as well? No. They will retain the screen name you had when you wrote the reviews and/or posts. Accounts may be locked for a variety of reasons including violating the Terms of Use.
If your login in fails please be sure: |
NavigationUse this clickpath: Click the "My Favorites" link in the black bar at the top of the site > click "Remove items" in the upper right of the page > use the red "X" on each item to remove it > Click "Remove items" again to turn off the functionality. The upload icon (the up arrow) is located in black top navigation bar on the right side. Where is my account information? Follow this clickpath: Clicking your "Screen Name" in the top black navigation bar > click "My Library" > click "Settings". Where are my bookmarks (favorites)? Bookmarks are now called favorites. To find them use this clickpath: click your screen name in the black top navigation bar > select "My Favorites"
Use these clickpaths: Where is a collection's full description? On a collection page either click "More" at the bottom of the description summary or, click the "About" tab Where are the 'most recent uploads'?
This feature is limited to the top media types. Use this clickpath: Where are the "picks" and "recommended items? At this time that feature is not part of archive.org |
QuestionsCan I upload live recordings that were broadcast on XM Radio or Sirius Satellite Radio? How do I search for an artist by date of the concerts? Should I upload checksum files like MD5 or ftp? I'm an artist who would like to be included in the Archive, what do I need to do? I have a different source for a show that is already in the archive, should I upload it anyway? Can bands place restrictions on material to be archived? Do you provide an RSS feed of new updates to the LMA? What does the 'Transferred by' field mean? Where can I find other recordings by [trade-friendly band] that aren't in the collection? What are the options for streaming a full recording? What file formats are accepted for contributions to the Live Music Archive? I like adding concerts. Do you have a preference on the way I put in information? Where can I see the rest of the 'Most Downloaded Items' in the Live Music Archive? I have more Live Music Archive questions...who do I ask? How can I add a logo to my collection page? How do I upload a show to the LMA? How are view (download) counts calculated? What is the Live Music Archive all about? What are the options for downloading a full recording? |
Live Music ArchiveCan I upload live recordings that were broadcast on XM Radio or Sirius Satellite Radio? At this point in time, Archive.org cannot host recordings that were broadcast over either of these services. Subscribers have informed us that they were required to sign a "Terms of Use" document that forbids the recording/hosting/rebroadcasting of any material received from these services. Until we hear otherwise, these recordings cannot be hosted here. A recording I uploaded and marked 'no lossy formats' had them created (mp3, ogg, m3u, etc...) . How can I remove them?
If you come across this situation and you are the uploader, click [edit], select the derivation option you prefer, and then 'Update'. You should see the message "Format Options Updated Successfully". Within 10 minutes the system will create a "_rules.conf" file in the recording's folder. Then, the next time the system performs an automatic sweep looking for changes, it will notice the new rules file and remove the lossy files automatically. The sweep occurs approximately twice a day, so you should see the files removed within 12-24 hours. How do I search for an artist by date of the concerts? As an example I'll search for Del McCoury: start at https://archive.org/details/etree type "Del McCoury in the "Search this Collection" text field on the right side and hit return. I prefer list view so I click the icon (the four stacked horizontal lines) all the way on the right side of the "SORT BY" bar. And, I check the "SHOW DETAILS" box to show more information. Now I've got results for Del McCoury in the Live Music Archive at https://archive.org/details/etree?&and[]=Del%20McCoury Now click the "DATE PUBLISHED" link in the "SORT BY" bar above the results. Now I've got them sorted by concert date from newest to oldest at https://archive.org/details/etree?and[]=Del+McCoury&sort=-date To reverse the order click the Up/Down arrows just to the left of the words "SORT BY in the "SORT BY" bar. Now they concert dates are from oldest to newest at https://archive.org/details/etree?and[]=Del+McCoury&sort=date The .txt file is used by the LMA collection to populate metadata in the item, especially the titles of tracks in the playlist. Please be sure it is a .txt file and not another text format. Should I upload checksum files like MD5 or ftp? We no longer require nor desire checksum or fingerprint files. Often they cause problems when files are changed in the item. Systems have improved to the point where we no longer see checksums as necessary to verify accurate upload/download. At this time, video uploads are not being accepted, namely because most of the bands archived prohibit the video taping of their shows. Moreover, unlike audio, where we actually have a shot at archiving the vast majority of any given band's live concerts (in very high quality format), video is scarce and, unless made by the artist (in which case, it's typically for commercial purposes), is not of particularly good quality. There's no set list for this show, or, The set list does not match up with the number of files. Should I submit an error report?
There has been an increasing number of shows uploaded to the Live Music collection without set list information, or the set list was not properly matched to the files. When you notice a recording like this, please email us (etree at this domain) only if you have an updated set list, or you are able to match the files up correctly.
I'm an artist who would like to be included in the Archive, what do I need to do?
We'd love to have you! Just write to us at etree at archive dot org in English giving some kind of permission for us to archive your shows for public download and noncommercial, royalty-free circulation. It does not need to be a formally worded declaration, and can come from anyone you feel has the "say-so." We just need to be clear on how you feel about the project. We will put relevant quotes onto a new "collection" page (examples) for your performances, along with a link to your official website.
I have a different source for a show that is already in the archive, should I upload it anyway? Yes! In keeping with the nature of this Archive, it is appropriate for multiple sources of the same show to be available for download. When you upload the new source, be sure to name the source in the show's top level folder to avoid confusion. Some bands do place limits on the types of sources allowed (such as soundboard recordings), so please check the policy for any given band. The progress of my upload says 'File metadata XML invalid. Waiting for user to correct.' How can I fix this?
This is typically caused by illegal symbols being used somewhere in the information that was put into one of the forms submitted with the show (either the import form or "File Options"). Double check that the only characters used are those visible on a standard English-language 104 key keyboard. More information and a few examples are here. Can bands place restrictions on material to be archived?
Yes. Each band can tailor the extent of their permission to the Archive. We quote the band's wishes in the Rights section of the band's Collection page. Here are some examples of special restrictions bands have requested. We point out different cases in a band's policy information using a shorthand "Limited Flag" tag.
Do you provide an RSS feed of new updates to the LMA? Indeed! The URL of the feed is http://www.archive.org/services/collection-rss.php?mediatype=etree&collection=etree You can plug this into a front end like AmphetaDesk (available at: http://www.amphetadesk.com) What does the 'Transferred by' field mean? This field indicates the person who did the original DAT/MD/Cassette to WAV conversion. Also, note that in the case of recordings made directly to laptops there is no transfer. Regarding removing the lossy files ... I edited my show, checked the box to remove them and clicked update. Now when I click update again, the box is still not checked. Why? It takes 2-10 minutes for your checking of that box to 'stick' ... see this discussion board post: http://www.archive.org/iathreads/post-view.php?id=22816 for an explanation of why. Where can I find other recordings by [trade-friendly band] that aren't in the collection? If the artist is OK with Internet trading, you may be able to find downloadable recordings through http://bt.etree.org. Also, check http://db.etree.org to find people who have copies of shows and who may be willing to trade. Etree.org has additional trading forums at http://forums.etree.org Lastly, you can check out a band's own fan forums and mailing lists. Good luck! In contrast, the Live Music Archive forum at the Internet Archive is not a good place to post about trades, or to ask for shows that are not yet archived here, whether or not the band presently has a section here. Moderators may delete these posts. More posting etiquette tips for that forum are here. What are the options for streaming a full recording?
Hi-Fi: An MP3 playlist, readable by most players, that has the addresses of MP3 files encoded with a variable bit rate. Lo-Fi: An MP3 playlist, readable by most players, that has the addresses of MP3 files encoded with at a constant bit rate of 64 kilobits per second. These files are ideal for users with slower Internet connections. What file formats are accepted for contributions to the Live Music Archive? Currently, the Live Music Archive will only accept lossless audio files in these formats: flac, aiff, wav or shn. Do not upload the lossy files (MP3 or OGG) next to your lossless format files. The derive task creates those automatically, provided that the contributor agrees to having them available. This ensures that all the files here have uniform quality options selected. Please follow etree.org's Seeding Guidelines when preparing your contributions for addition to the collection. Pay particular attention to the Naming Standards section. A well-named identifier helps patrons find your show in our large collection. A well-named set of files allows files to be listed in the proper order at the site, and allows patrons to listen to them in playlists and burn them to CD in the proper order, too. I like adding concerts. Do you have a preference on the way I put in information? Yes, here are some guidelines that will help us maintain good records for each concert.
Where can I see the rest of the 'Most Downloaded Items' in the Live Music Archive? To view the entire Live Music Archive (everything in the "etree collection") sorted by 'Most Downloaded Items' go to this link: http://www.archive.org/search.php?query=collection%3Aetree&sort=-%2Fmetadata%2Fdownloads And here's one that lists everything but the Grateful Dead (like the one on the LMA front page): I have more Live Music Archive questions...who do I ask? Feel free to email etree@archive.org with any questions, and we'll do our best to post the answers here as soon as possible. Also, the message board is a great resource; with so many helpful, knowledgeable folks out there, you can often get a speedy answer to your question. How can I add a logo to my collection page? Yes. Follow this clickpath: drag and image over the existing one next tot he band name > click the submit button > wiat for the tasks to complete > refresh the page. These image formats will work: jpg, png or gif The image you upload should be named identifier (where identifier is your item's identifier name) followed by the format. So, identifier.jpg, identifier.png or identifier.gif will work. How do I upload a show to the LMA?
Uploading instructions for the etree collections can be found at https://archive.org/download/lmaupload/lmaupload.html
How are view (download) counts calculated? Views (formerly known as downloads) are calculated per item page, per IP address, per day. If you stream a show today, that's one download. If you view the txt file tomorrow, that's another download. If you download every file from a show's page the next day, that counts as one more download. If you download the same file a thousand times the day after that, that still only counts as one more download. What is the Live Music Archive all about?
This audio archive is an online public library of live recordings available for royalty-free, no-cost public downloads. We only host material by trade-friendly artists: those who like the idea of noncommercial distribution of some or all of their live material. Live recordings are a part of our culture and might be lost in 100 years if they're not archived. We think music matters and want to preserve it for future generations.
What are the options for downloading a full recording?
Lossless: A ZIP file containing Shorten files or Flac files. Unlike formats like MP3, lossless formats are true to the original - there is no degradation in quality. Hi-Fi: A ZIP file containing MP3 files encoded with a variable bit rate to deliver high quality at roughly 160kilobits per second. Lo-Fi: A ZIP file containing MP3 files encoded at a constant bit rate of 64 kilobits per second. These files are ideal for users with slower Internet connections. Other Web Options: All files are displayed as individual links on any item's details page. Web-based download managers can be set up to download all the files you want from the page, as a group. For Firefox, the extension DownThemAll is a popular option. BitTorrent: Some Items that are downloadable via HTTP are also downloadable via a BitTorrent client; these items show a 'Torrent' link next to the 'HTTP' download link. (To trigger creation of a BitTorrent file for an item in the LMA that does not yet have one, write a review for it, e.g. "Make me a Torrent!"). Note: only items downloadable via HTTP can be downloaded via BitTorrent. How can I help get bands into the Live Music Archive?
If you know of a trade-friendly live-performing band that is a good candidate for the Archive, you can initiate contact. Some tips and letter templates can be found here. When you write, make it clear you are asking about the Live Music Archive at archive.org. Don't just ask about their general taping/trading stance. We want bands to know what's up.
How do I make corrections to shows?
Sometimes people make typos or other mistakes on uploads, or leave gaps in info that can be filled in later. You can help supply good information for archived items. Here is the current best method to submit corrections:
|
QuestionsHow do I specify an HD derive? Should I use the html5 or Flash player? How can I link to a start in the middle of a movie? My movie doesn't start fast or buffers a lot? Sometimes when I play a movie, the video is choppy or very pixelated. Why is that? Why do I get errors when I try to play a movie? Who owns the rights to these movies? What kind of movie file should I submit? What are the archive.org encoding specification? |
MoviesHow do I specify an HD derive? At this time we do not derive HD files. HD files need to be derived by our system for the HD button to appear in the player. Click the "Share" icon near the player. A popup window will offer URLs for embedding. For more advance options click the "Advanced embedding details, examples, and help!" link at the bottom of the popup. Should I use the html5 or Flash player? The html5 audio player is the default player. Some browsers may prefer to use Flash. Clicking the "lightning bolt" icon on the right side of the player will with it to a Flash based player. How can I link to a start in the middle of a movie? To set a start time add ?start=XXX (where XXX is the start time calculated in seconds) to the end of the URL. At this time there is not a way to specify the end time. If a hi-res source file was uploaded it will be available in the DOWNLOAD OPTIONS section or by clicking SEE ALL. An editable file is a file which can be downloaded and used in an editing program. The MPEG-4 are the highest bitrate versions we could do with the linux mpeg-2 to mpeg-4 conversion tools we use. These files can be read directly into FinalCut-Pro from Apple, and can be converted to mov using Quicktime-pro and read directly into iMovie from Apple.
There are several programs you can use to stream movies in the Archive. Because we allow users to upload video files in any format, the same player will not always work for every single file, so it's a good idea to have a couple of programs available that you can try. Also, some files simply can't be streamed. Usually, this happens when the program that created the video file uses a codec that our software doesn't understand. So if you click on a stream link and get an "unsupported media" sort of error, use the download links instead. Here are some free players that might come in handy: Quicktime VLC Media Player So, if you were trying to stream the movie Duck and Cover found at http://www.archive.org/details/DuckandC1951 you would: VLC will stream mp4, avi, mpg and other file formats, so it is quite useful for viewing the majority of the files in the archive. Real Player We support two bitrates: 32Kbps-192Kbps for modem and ISDN users plus 256Kbps-450Kbps for DSL and cable-modem users. My movie doesn't start fast or buffers a lot? The in browser player typically uses an mp4 file. Most encoding (codecs) that are used do not add a "fast start atom" to the file to get it to start without the file having to load. If you are uploading an mp4 it is best to use .mpeg4 rather than .mp4 as the extension in the file name. That way our system will create an mp4 with the fast start atom. Sometimes when I play a movie, the video is choppy or very pixelated. Why is that?
Try downloading the movie to your computer and watching it locally. Sometimes choppiness occurs when we can't stream it to you quickly enough (because your connection is slow or our servers are overloaded). If you're watching an MPEG-4 that we derived from an original MPEG-2, we first reduce its size to 320 x 240 - a quarter of the resolution of NTSC video. We then translate it at 350 kbps, which is really borderline for that resolution. You see errors occasionally because there simply isn't enough bandwidth available, so the MPEG-4 encoder either drops frames - resulting in jerky or choppy motion - or drops macro blocks - resulting in blurred or pixelated video. That is the price we pay for the small file size - 80 MB for a 1/2-hour clip is really very small in the digital video world. If this is the case, download the original MPEG-2 to solve the problem. Why do I get errors when I try to play a movie?
The best all-around, free player is VLC Media Player - it handles most of the movie files you will find on this site. If you're seeing errors when you try to play movies, please try downloading VLC and using that instead. This clears up many people's problems. Here are some other possible problems:
If you still have trouble, post your question to the moving images forum. Who owns the rights to these movies?
This will vary from movie to movie. Many of the movies and collections are licensed with Creative Commons Licenses. Uploaders may designate whether or not an item has a CC License. If they do so, the Creative Commons logo will appear on the left hand side of the movie's detail page. Click on this logo to see details about the specific type of license that the uploader has assigned to the movie. Archive.org cannot guarantee the accuracy of uploader-provided information. Some films may have the contact information listed for the filmmaker. If the information is provided, feel free to contact the filmmaker or organization the film comes from.
You may upload movies that you own the copyright to, or that are in the public domain. We are not copyright lawyers, and copyright is a tricky business, so you may want to consult a copyright researcher to clear material before you use it. You may also want to check this list of movies that one of our volunteers has already researched. Here is some general information on the subject that may help you decide if your movie is okay to upload. The information below applies to films produced in the United States only. 1) Is there a copyright notice visible in the film? It is usually visible with the title or at the end of the film. If the work was made in 1923 or earlier, it is probably public domain and can be uploaded. NOTE! Restored versions of the film or new soundtracks for silent films can have more recent copyrights that are still valid - usually a copyright notice for a new soundtrack or restoration will appear in the film. For works made from 1923 to 1949, post a question to the movie forum on this site before you upload. The copyright could have been renewed and there isn't a way online to check a film's copyright status. For works made from 1950 to 1963, you can check the title at the Library of Congress Copyright Database for copyright renewals: http://www.copyright.gov/records/cohm.html . This will list copyright renewals for most films. If the copyright notice is 1964 or later, the copyright is probably still valid and the film should not be uploaded unless you are the copyright holder. 2) Is the copyright notice in the correct format? It needs to state three things - the word 'copyright' or the copyright symbol or '(c)', the year and who owns the copyright? If it is missing one of those elements or if there is no notice, it could be public domain. If you aren't sure, please post a question to the movie forum on this site. 3) Is the film foreign (not from the U.S.)? Foreign titles might not have a copyright notice, but still may be copyrighted in their country of origin. Traditionally the U.S. wouldn't recognize the copyright of a foreign film unless it was registered in the U.S. That has recently changed with the GATT treaty. Many foreign works had their copyrights restored. Please post a question to the movie forum on this site about these films before you upload. What kind of movie file should I submit?
The archive is all about free access to information, so you should submit file formats that are easily downloadable and/or streamable for other site patrons. We prefer that you submit the highest quality format that you have available, and then we will attempt to create smaller file sizes and formats automatically with our deriver program. MPEG2 files are the easiest file type for us to deal with. We recommend that you do not attempt to do any special encoding of your files - the more settings you mess around with, the less likely our deriver code will be able to process the file. Whatever format you choose, please upload each file to your item individually, in a non-compressed format. Uploading content in a .zip or .rar file makes your item unstreamable and significantly less accessible to others. If you upload .zip, .rar, non-video formats (like .exe), or password-protected files, they may be removed by our moderators. The table on the Derivative Formats page shown below describes what file formats we will attempt to derive depending on what type of file you submit. What are the archive.org encoding specification? You can find the specs we use for encoding in the "Additional info on audio/video derivatives" section Can I change the static start image in the movie player? That is not possible at this time. You can upload a properly formatted .srt file for closed captioning. The file should be named IDENTIFIER.srt. If you have more than one language add the language to the file name e.g. IDENTIFIER_english.srt Yes. Once the video is started and file has sufficiently loaded you can see thumbnails by mousing over the playbar. They should pop up above the playbar. |

The Internet ArcadeHow is it Playing Arcade Games in my Browser? The Internet Arcade uses a program called JSMESS, which is a Javascript port of the MESS and MAME emulator projects. MESS/MAME have been developed over nearly 20 years and are able to emulate hundreds of computer systems and thousands of console and arcade games. A volunteer group has been able to convert MESS/MAME into pure Javascript and make it run in most modern browsers. The Internet Arcade is a collection of emulated arcade games from the 1970s-1990s that can be played in your browser. It is located here. There are similar collections of playable console games (the Console Living Room) and general computer software (the Software Library). There are no plugins needed to run the Internet Arcade. It uses 100% Javascript (not to be confused with Java), which is a scripting module inside all modern browsers that has great flexibility for running code, playing sound and video, and doing everything necessary to provide an arcade game in a window. Ironically, if the system is not working for you, a plugin may be preventing it: there are a number of plugins, such as NoScript, which automatically turn off Javascript processing for a site and require you to turn it back to run. If that is the case, the Arcade will not function - please enable Javascript on archive.org to run the Arcade. How do I Play a Game on the Arcade?: In each entry for a game on the Arcade, you are taken to a page with a description of the game, and a screenshot in the right-hand corner of the gameplay. A line underneath the screenshot says "Run an in-browser emulation of the program". You can click on the screenshot or the word "Run" to go to the Player page. On the Player page, you are shown a box and underneath it controls for Fullscreen, Mute/Unmute, Dark Background, and possibly others. Inside the box, there should be a MAME or MESS logo. Clicking inside this box, or hitting the spacebar, should start a disk icon spinning and the program will load. When the program is finished loading, the disk icon will stop spinning and the box will expand out to the resolution of the given program. At this point, the arcade machine will begin running. If you do not see the MESS/MAME logo, the program will not start. See other FAQ questions for possible solutions to this problem. I Don't See Anything in the Box. If you do not see a MAME/MESS logo in the box above the "Fullscreen, Dark Background, Mute" buttons on the player page, then JSMESS is not running in your browser for some reason. Some possible reasons to investigate:
For reasons that we will explain, sound is muted by default on JSMESS. To enable sound, you (currently) need to start a program (i.e., click on the logo), wait for the arcade machine to start, and then hit the "Unmute" button at the bottom of the running game. This will set a cookie for "Unmute" and after you hit Refresh (F5) on your browser, all later games will have sound. We are aware this is clunky, and intend to rewrite our Player to more intuitively work in the future. The Sound Sounds Horrible/Scratchy/Distorted! The JSMESS program uses a standard called "Web Audio" that is still in its early stages - as a result, the JSMESS program is extremely burdensome to this standard, and unless your machine is very fast and the arcade game being run a simpler one, the sound can easily distort, even when doing something like switching between tabs or moving the mouse! This is why the program is, by default, muted. As of November, 2014, a new Web Audio specification has been proposed that allows Javascript programs like JSMESS to run audio more dependably, as we expect for sound and video, and the committees in charge of this specification are very aware of JSMESS as a real-world example of how to improve their specification. We currently can only wait, at which point newer versions of browsers will have much better sound. Sometimes, a refresh/restart of the arcade player page will bring the sound back into shape, for at least a while. Why did the Arcade Game start with All Sorts of Weird Graphics? The JSMESS system provides an as-accurate-as-possible presentation of an arcade machine when it is powered on. A large amount of arcade machines had "boot-up" or "checksum" sequences, where they would show a variety of messages and graphics to indicate the state and quality of the machine. If a ROM chip failed, or a circuit had burned out, various error messages would show and the arcade machine owner or operator would have to do hardware repairs. This situation continues in the emulations, although the machines are generally not going to blow a fuse or lose hardware. That said, there are a very small number of machines that will start up, and then sit at a cryptic operations message, or be awaiting a key. Where possible, the instructions underneath the game's video window will give information on what key or keys to press to have the game continue to boot up properly. At the bottom it mentions a Gamepad. Do I need a Gamepad? Every arcade game can be played using your keyboard; no gamepad or joysticks are needed. That said, it is possible under some circumstances to hook a USB Gamepad to your computer and have it recognized. |
QuestionsI need help choosing a license? Why is there more than one type of upload page? What is the "Test Collection" for? My upload failed. What do I do? Where can I see all my uploads? How long does it take before my stuff is ready/derived? Should I upload a MARC record file for a book? Is there a limit to what I can upload? What upload apis do you offer? What kinds of formats do you want me to use for uploading? How can I take my files off the site? Why can't I upload a meta.xml file? What languages are supported by Archive.org? How can I use accented or special characters in my title or description? How many files and how much data can I upload to a single item? How do I add a file to an existing item |
Uploading Content
You may contribute content to the Internet Archive if it's in the public domain or if you own the rights to it. Please refer to the Terms of Use. Please note that if you wish to be contacted with inquiries regarding your item, you'll need to supply public contact information. Some chose to provide a web address, mailing address, or other means of contact in the description text for the item.
1. Log in and click the upload icon in the top black navigation bar
Support for Filenames is limited to basic ASCII characters. I need help choosing a license? From the Creative Commons website: "Creative Commons licenses help you share your work but while keeping your copyright. Other people can copy and distribute your work, but only on certain conditions." You can choose a license to associate with your contribution and this license will be linked to when users see the details page. Why is there more than one type of upload page?
There are currently 3 in-browser options for uploading at archive.org/upload: What is the "Test Collection" for?
We provide a Test Collection for uploading test items. There are two considerations for uploading to this collection: My upload failed. What do I do? If you see the "Resume" button it indicates that the upload likely failed due to some network interruption. You may click the "Resume" button to continue uploading. It may take several tries. If it continually fails the only option is to refresh the page and start the upload again. Where can I see all my uploads?
Use this clickpath from any page: For bulk or automated uploading we offer a python wrapper. It required some comfort in a unix environment. It can be found at github.com/jjjake/internetarchive How long does it take before my stuff is ready/derived? The time before the item is has completed its task can range from a few seconds to a few hours and in some cases, days. It is dependent on a number of factors including the type and size of files as well as the load on the system. To check an item's history: on the /details/ page click the "History" link on the left side of the page next to the title. Should I upload a MARC record file for a book? A MARC record will populate an item as soon as the item derives if the MARC file is named correctly. If it's a binary (ISO 2709) MARC, it should be called {itemID}_meta.mrc, If it's MARCXML, it should be called {itemID}_marc.xml. Is there a limit to what I can upload? At this time there is no limit. Due to system architecture we recommend that item pages not exceed either 1000files or 25GB. Yes. We duplicate/backup all files at various locations. What upload apis do you offer? For bulk or automated uploading we offer a python wrapper. It required some comfort in a unix environment. If you wish to use this please contact us at info@archive.org and we can provide additional information. What kinds of formats do you want me to use for uploading? We encourage users making contributions to the Archive to create as high quality versions of their media as possible. Most typical formats are acceptable. Please do not upload encrypted or executable files as these may be removed. At this time we have no fees for uploading and preserving materials. We estimate that permanent storage costs us approximately $2.00US per gigabyte. While there are no fees we always appreciate donations to offset these costs. As an archive our intention is to store and make materials in perpetuity.
There are several reasons you may not be able to locate items you created: How can I take my files off the site?
If you would like us to take down an item you have posted, please send an email to info [AT] archive [DOT] org. Please include the exact URLs of the items. Your email must come from the same email address you used to upload the item. Why can't I upload a meta.xml file? The architecture of the system does not allow uploading of meta.xml files. Attempts to do so will encounter an error. What languages are supported by Archive.org? Archive.org supports all metadata about items in just about any language so long as the characters are UTF8 encoded. How can I use accented or special characters in my title or description? You can use accented and other special characters in your item text and file titles, but you need to make sure you use the xml-safe code for those characters instead of typing them directly into the forms. Typing accented characters directly into forms can break the xml for your item, making your files unavailable through the site. Instead, you'll want to use a special code to represent those letters. You can find a complete listing of these codes on http://en.wikipedia.org/wiki/List_of_XML_and_HTML_character_entity_references . How many files and how much data can I upload to a single item? Because items can "break" we typically recommend that you not exceed 1,000 files and/or 25GB per item page. You can upload very large files, unto 100GB. However, large files that require deriving may take a very long time or even timeout and fail. How do I add a file to an existing item
There are two ways. clickpath: How do I prevent lossy formats from being derived
This is only possible for audio items.
Support for Filenames is limited to basic ASCII characters. |
QuestionsHow do I read the books in other formats, like ePub, Mobi, DJVU? I want to scan a book. What resolution should I scan at? What file format should I upload? What formats are derived from my source file? Why is OCR so bad? Why do the epub, djvu, mobi, text files have garbled or missing text? My subject tags are lumped together. How do I fix that? How do I change the title page in the flip book? Where are the hi-res images in an item? Where are the thumbnail images? How do I report that something's wrong with a book? |
Books and Texts
On the item details page click the expand icon (four arrows aiming out) to the right of the book preview image. Usually you can click the PDF link and it will open in your browser. Otherwise you should download the pdf file and read it on your device using a reader such as Adobe Acrobat Reader. How do I read the books in other formats, like ePub, Mobi, DJVU? • ePub is an open textual format (not images of pages). Many readers are available. A free one is from Adobe. • Mobi is a proprietary textual format from Amazon supported on the Kindle. • DjVu is an open format for scanned documents with free readers for windows, mac os-x, linux. It is compact, searchable, good looking, and open format. I want to scan a book. What resolution should I scan at? Hi-resolution originals are always preferred. We scan at 600dpi. What file format should I upload? A hi-res pdf is the easiest format to upload. To upload image files read the "How do I make a flip book out of loose images" section of this FAQ. You can upload a MARC record with your text file. The MARC record will populate the item as soon as the item derives if the MARC file is named correctly. If it's a binary (ISO 2709) MARC, it should be called {itemID}_meta.mrc, If it's MARCXML, it should be called {itemID}_marc.xml. What formats are derived from my source file? Please refer to this chart for the formats typically derived. Why is OCR so bad? Why do the epub, djvu, mobi, text files have garbled or missing text? OCR (Optical Character Recognition) is inexact. Sometimes it can be poor. It largely relies on factors of the physical book such as type font, color, cleanliness of the page, language (some are not OCRable at this time), and page orientation (sometimes charts are turned at 90°). At this time we do not offer a way for you to either correct bad OCR or add your own corrected OCR file. Several of the derived file formats such as mobi, epub and djvu rely on OCR. So, if the OCR is poor, those files will also have garbled or misspelled words. My subject tags are lumped together. How do I fix that? Because MARC records use commas and semi-colons archive.org text items do not honor those characters as a way to separate subject keywords. To separate them you need to create individual metadata key:value pairs for each subject. To do this in the upload form (archive.org/upload) add your first subject in the "Subject Tags*" field. For any additional subjects follow this clickpath: Add additional metadata... (in the More Options cell) > in the left field key in "subject" (without quotes) > add your subject in the right field > repeat if there are more subjects How do I change the title page in the flip book? Our system attempts to detect the title page of a book. The basic criteria is dependent on OCR. It will try to choose the first page with large font size that best matches the title you used for the item page. If that fails it is somewhat random. To change the title page follow these click paths: On the item details page click SHOW ALL > right-click or control-click the scan data.xml file link and select "Save link as.... to download it > open the scandata.xml file in a plain text editing application > find "Title" and replace it with "Normal" >On the leaf you want to be the first page replace "Normal" with "Title" > Now replace the existing file with this modified one: On the items details page click "Edit > change the files > right-click or control-click on the scan data.xml file > select "Delete" > click OK >click the "Classic Upload" button > select the modified scandata.xml file on your computer > click Open to upload it > when the upload is complete click the "Update Item" button. Where are the hi-res images in an item? All files for an item can be found on the ALL FILES page. For books scanned by the Internet Archive the largest compressed (tar or zip) file holds the original scans. You can usually download this file, expand it and use the images. Where are the thumbnail images? To view thumbnails click the expand icon (four arrows aiming out) to the right of the book preview. In the book reader click the thumbnails icon (four squares) at the bottom of the page. On the item details page click the expand icon (for arrows pointing outward) > in the bookreader click the Share icon (3 dots linked together) > the popup window will offer several links. On the item details page click the "Share" icon to the right of the book preview. A popup window will offer URLs for embedding. For more advance options click the "Advanced embedding details, examples, and help!" link at the bottom of the popup. How do I report that something's wrong with a book? Please send a description of the problem along with the URL of the page to info@archive.org. Thank you. Please be aware that we typically do not modify the metadata of an item that has been created by a user of the site except at their request. We recommend leaving a review on the page explaining the issue. The uploader will automatically be notified. For volume and serial work the publish date often appears to be incorrect. This is because the metadata is populated by a MARC record from one of our partner libraries such as the Library of Congress. At this time volume and serial works are considered to be a single work so there is a single MARC record for it. Typically the date that the first volume was publish is the only date in the record so that is the date that will appear on all volumes of the work regardless of the date that might be printed in a particular volume. What is the directory structure for the texts? All files related to an item page reside in the pages directory. Below is a brief explanation of the purpose of each file: IDENTIFIER.djvu IDENTIFIER.epub IDENTIFIER.gif IDENTIFIER.pdf IDENTIFIER_abbyy.gz IDENTIFIER_archive.torrent IDENTIFIER_dc.xml IDENTIFIER_djvu.txt IDENTIFIER_djvu.xml IDENTIFIER_files.xml IDENTIFIER_jp2.zip IDENTIFIER_marc.xml IDENTIFIER_meta.mrc IDENTIFIER_meta.xml IDENTIFIER_metasource.xml IDENTIFIER_orig_jp2.tar IDENTIFIER_scandata.xml IDENTIFIER_toc.xml Open Library is an open project with the mission of having one web page for every book ever published. The software is open, the data are open, the documentation is open, and we welcome your contribution. Whether you fix a typo, add a book, or write a widget--it's all welcome. We have a small team of fantastic programmers who have accomplished a lot, but we can't do it alone! There are no books on Open Library. There may be links to books that are housed on archive.org or links to where you might be able to find the book elsewhere. There is also a lending program where you can borrow up to five books at a time for two weeks. You may find answers to questions about on the Open Library FAQ page How do I make a flip book out of loose images?
To make a flip book you need to upload a zip or tar that contains the files. Here's how: For more detailed information visit uploading-images-for-text-items/ |

RightsCan I use this ____ for ____ ?
Internet Archive does not itself seek to limit use of its digital materials. However, we cannot give ironclad guarantees as to the copyright status of items in our Collections and cannot guarantee information posted on item details or collection pages regarding copyright or other intellectual property rights. Our terms of use (https://www.archive.org/about/terms.php) require that users make use of Internet Archive's Collections at their own risk and ensure that such use is non-infringing and in accordance with all applicable laws. The person who uploads an item often provides information related to use rights, either by way of directly entering it in the description field or by selection of a Creative Commons license. The latter, if included by the uploader, will be viewable via a Creative Commons logo on the details page, which serves as a link to a description of the specific type of license that the uploader has assigned. One way to attempt to contact an uploader about information that they have posted is to post a review to the item. The Internet Archive strives to follow the Oakland Archive Policy for Managing Removal Requests And Preserving Archival Integrity.
You may also find these resources helpful: Chilling Effects Clearinghouse Chilling Effects Clearinghouse Electronic Frontier Foundation Electronic Frontier Foundation
Please see also: Who owns the rights to these movies? https://www.archive.org/about/faqs.php#49 Are there restrictions on the use of the Prelinger Films? https://www.archive.org/about/faqs.php#197 Can I search Archive.org by Creative Commons License? https://www.archive.org/about/faqs.php#263
What is non-Commercial Use? Please see https://www.archive.org/iathreads/post-view.php?id=111591
A link the Terms of Use for Archive.org is at the bottom of each page.
How can I contact the person / group who uploaded an item? Internet Archive is unable to release any contact information for patrons. However, it may be worth your while to post a review for the item in question - this automatically contacts the uploader's account, notifying them that their upload has been reviewed. You could pose queries/requests for information therein. |
Downloading ContentWhy can't I download "Stream Only" files? These files are restricted to online use only and are not downloadable.
At this time there are two methods to do bulk downloading. Both require some comfort working in a unix environment: How do I download just one file?
Start on the item's details page. Use this clickpath: How do I download all the files in just one format? Start on the item's details page. In the "Download Options" click the format you want to download. If there are multiple files in that format you will be prompted to download a zip file containing all the files in that format. If there is only one file in that format it will either open in your browser (a pdf for example) or download if it is a format that does not render in your browser (such as epub). How do I download all the source/original files and metadata Start on the item's details page. In the "Download Options" click the "[number] Originals" link in the lower right side. You will be prompted to download a zip file containing all the original files How do I download all the files in an item? Start on the item's details page. In the "Download Options" click the "[number] Files" link in the lower right side. You will be prompted to download a zip file containing all the original files What are all the derived file formats for?
Generally speaking there are three categories: This page shows the files typically derived from the uploaded source files. (Note: The system will not derive a file format that is a duplicate of the source file uploaded. So if an mp3 is uploaded the system will not derive an mp3 from it.) Why can't I download/view this book? Due to rights issues some books may only be available in DAISY (Digital Accessible Information System) format. This format is specifically for text to audio devices for the print-disabled community. for more information on DAISY see https://archive.org/help/derivatives.php |
Item page managementHow can I add custom metadata to my item?
Use this clickpath from the item's details page: You can only modify items that you created. How do I delete files in an existing item?
Use this clickpath from the item's details page: I can't edit an item I uploaded There are two likely reasons for this: 1. The server where the item lives is temporarily in a read only state. Usually it is fixed and back to a read/write state in a day or less. One way to tell if this is the case is to click the "History" link on the item page. If the server id has a yellow stripe over it then that server is read only. Please be patient and check your item later. 2. You changed your account email address. If this is the case please contact us at info@archive.org. Include your old email, new email and we can move the old items to your current email address. How do I report spam items or site abuse? Please send email including the URL of the item page(s) and a description of the problem/error. Send it to info@archive.org. What is an item and how do I create one?
For simplicity think of a page on the site as an "item". A special page that groups items is termed a collection. To create an item: How do I edit metadata of my item?
For existing items use this clickpath from the item's details page: You can only modify items that you created. |
QuestionsWhat books can I borrow? How can I find them? Which reading devices can be used to read the eBooks borrowed through archive.org? How many books can I check out at once? How can I see which books I've checked out? Can I put a library book on hold? Where do I get Adobe Digital Editions? How do I authorize Adobe Digital Editions? Who is my ebook vendor? Can I read or borrow books on my Kindle? How does borrowing a book work through archive.org? |
Borrow from Lending LibraryWhat books can I borrow? How can I find them? The easiest way to find books to borrow is to jump straight to the Lending Library which shows works which have editions that are available through the Internet Archive. Which reading devices can be used to read the eBooks borrowed through archive.org? Internet Archive offers borrowable books in BookReader, PDF and ePub formats. BookReader editions may be read online immediately in any web browser. Downloadable eBooks are readable in Adobe Digital Editions and some other software platforms. Here is a list of supported devices on Adobe's website. ADE also provides support for Sony's Reader. How many books can I check out at once? You can borrow 5 books at a time from archive.org. Each loan will expire after 2 weeks and will automatically "return" at the end of that time period. How can I see which books I've checked out? There's a page under your archive.org Account which displays all the books you've checked out at any one time - https://archive.org/account/loans.php. Additionally you can see your loan history by going to https://archive.org/account/your Account page and clicking the "Profile" link. Can I put a library book on hold? Yes. If you try to borrow a book that is currently on loan you will be offered a link to be put on a waiting list. You will be notified via email when the book becomes available. Where do I get Adobe Digital Editions? You can download Adobe Digital Editions from adobe.com. It's free. If you are using a device that can not run Adobe Digital Editions, you still need an Adobe account. You can get one online here. An older version of Adobe Digital Editions can be found at this link. How do I authorize Adobe Digital Editions? Who is my ebook vendor?
The first time you run Adobe Digital Editions, it will prompt you for authorization. This is completely optional and is not linked to your archive.org ID. If you do not want to set up an Adobe ID, check the box in the lower left where it says "I want to Authorize my computer without an ID" and click Authorize.
Regardless of which ereader you have, you can read archive.org eBooks online in your browser with our BookReader. Many devices support PDF files, which can be downloaded from archive.org. Below are some tips for using some popular ereader devices. Feel free to send your feedback and questions to info@archive.org. Can I read or borrow books on my Kindle?
The procedure varies depending what model Kindle you have.
How does borrowing a book work through archive.org?
The Internet Archive and participating libraries have selected digitized books from their collections that are available to be borrowed by one patron at a time from anywhere in the world for free. These books are in BookReader, PDF and ePub formats (and Daisy for the print disabled). You can choose which format you prefer as you complete the borrowing process.
Can I borrow books on my Ipad or Android tablet?
Yes! You can read our books using our BookReader via your browser or by using a reader app like Bluefire Reader or Overdrive Media Console (iPad) or Aldiko Book Reader or Overdrive Media Console (Android tablet). For more information on Bluefire, go to their site at bluefirereader.com. Before you start, register an Adobe ID. You'll need to do this once. If you don't have one, create one at this page.
Can I return a library book early?
Yes, usually. If you borrowed a BookReader edition, simply return it from your Loans page.
|
![[screenshot of Adobe Digital Editions library page]](../../ia801701.us.archive.org/21/items/olimages/ADE-screenshot.jpg "[screenshot of Adobe Digital Editions library page]")
{kind=link}
{kind=link}
The Grateful Dead CollectionAbout the Grateful Dead collection: Audience-made Grateful Dead concert recordings are available as downloads while available soundboards are accessible in streaming format only. The Grateful Dead is separated from the Live Music Archive into its own collection (with its own forum) to avoid confusion about lossless availability. The metadata and reviews for shows and recordings, even those not available for regular download, will remain available for those who maintain direct links. No filesets have been deleted from the Archive; certain items are simply not public now. Text files are available at a separate database. At this time, the Grateful Dead collection is not open to public uploads. The Grateful Dead Internet Archive Project (GDIAP) will continue its direct management of this collection for the time being. As far as we know, there has been no change to standard GD fan trading. It is common for bands to have policies that differ between fan trading, versus archiving here. How do I search by date, by year? On the Collection page you will see the years in the right hand column. Clicking them launches searches for those years. Where is "on this day in history"? You can find this in the About tab. This is done at the request of the band. What are some not even available as stream only? Shows that have been released commercially are not available. Where is the recording information? If that information is in an item you will be able to see it on the details page. Recording metadata may include details page you may include: Source - the path from original source to final file format Taped by - the original taper Transferred by - the person(s) who processed the audio to the final file that was uploaded Why can't I upload to the Grateful Dead collection? At this time uploads by the public are prohibited at the request of the band. At this time uploads by the public are prohibited at the request of the band. |
Report ItemHow do I report that there's an issue with an item?
The Internet Archive (Archive.org) is a nonprofit library that preserves digital cultural artifacts, and provides online access to over a million users a day with the goal of universal access to all knowledge. To report an item that violates the Internet Archive's Terms of Use, please send an email with the URL (web address) of the item to info -at- archive.org The Internet Archive strives to follow the Oakland Archive Policy for Managing Removal Requests And Preserving Archival Integrity. (When reviewing the Oakland Archive Policy, please note that information about requests coming from webmasters is information to assist with archived websites in particular.) There's a problem with the item, what's next?
Some changes to our system, to individual items, or to collections can take a day to appear on Archive.org. If you're experiencing a problem with an item, we recommend trying again after a day. Often the issue will then have already been resolved.
How can I take my file off the site?
If you would like us to take down an item that you have uploaded, please send an email to info -at- archive.org Please note that you need to include the URL (web address) of the item. Your email must come from the same email address you used to upload the item. This is the only way we can tell that you are the owner of the item. As always, if you write in, please be sure any spam filter you have is set to accept email from @archive.org. Please see also the further resources at https://www.archive.org/about/faqs.php#Uploading_Content How do I report that something's wrong with a book?
If you see an error with a book that the Internet Archive has digitized, we'd appreciate knowing about it! Please send an email with the URL (web address) of the book, and description of the problem, to info -at- archive.org In some cases, you may know of alternate information about a book that is supplemental to the library bibliographic record. (For example, a new, more modern transliteration of an author's name.) To share additional information like this, you may wish to post it using the option to write a review of a book. For more information on the Internet Archive's sponsored scanning, For more information on books that users upload, or for information on how to upload your own, |
ForumsHow can I make links clickable in my posts? You may have noticed that some posts have highlighted links in them. Internet Archive forums permit the use of HTML codes. Suppose you want to make a link to the Internet Archive home page, one that looks like this: Internet Archive home page. To do this, you would enter the following HTML code: <a href="http://www.archive.org">Internet Archive home page</a>. How can I format text in my posts Since the Internet Archive forum system accepts HTML codes, you can make text bold, italic, underlined, or even colored by using normal HTML codes. See WebMonkey for a list of HTML codes. How do I subscribe/unsubscribe to a forum email list? Next to all forums, you will see a small envelope. When logged in, you can click on this envelope which will allow you to subscribe or unsubscribe to any forum. |
Questions |
Archive-It
Archive-It is a subscription service that allows institutions to build and preserve collections of born digital content. Through the user-friendly web application, Archive-It partners can harvest, catalog, manage, and browse their archived collections. Collections are hosted at the Internet Archive data center and are accessible to the public with full-text search. Why would I subscribe to Archive-It instead of using the Wayback machine at Internet Archive? Partners to this service can create distinct Web archives called "collections", containing only the born digital content they are interested in harvesting, at whatever frequency suits their needs. All collections are full-text searchable. The collections created with Archive-It can be cataloged with metadata and managed directly by the partner. The Archive-It service maintains a minimum of two copies of each collection online, a primary and a back-up copy. How frequently can I archive Web sites? Archive-It is very flexible: you can harvest material from the Web using ten different frequencies, from daily to annually. Partners can select different crawl frequencies for each chosen URL. Additionally, your institution can also chose to start a crawl "on demand" in the case of an unforeseen spontaneous or historic event. Who gets access to the collections created in Archive-It? By default, all collections are available for public access from the main page at www.archive-it.org. However, a partner can choose to have their collection(s) made private by special arrangement. How can I search the collections? Archive-It provides full text search capability for all public collections. You can also browse by URL from the list provided for each collection. The public can browse and search collections by partner type or collection from www.archive-it.org. What types of institutions can subscribe to Archive-It? Archive-It is designed to fit the needs of many types of organizations. The 190+ partners include state archives and libraries, university libraries, federal institutions, non government non profits, museums, art libraries, and local city governments. Who decides which content to archive in Archive-It? Partners develop their own collections and have complete control over which content to archive within those collections. Where is the data stored for Archive-It collections? All data created using the Archive-It service is hosted and stored by
the Internet Archive. We store two copies online and are working with
partners to have redundant copies in other locations. Partners can also request a copy of their data for local use and preservation to be shipped either on a hard drive or over the internet.
|
EquipmentWhat equipment does the Internet Archive use? What APIs?
Storage systems used by the Internet Archive: Equipment and software used in the Internet Archive's scanning and OCR services for Contributing Libraries Documents describing how to use Archive software and services, maintain "special" servers, and so on. Includes our API to archive.org services using JSON format. |
New PostFAQ Forum email rss RSS
View more forum posts